🖥️ Monitorizar tu servidor Linux como un profesional: CPU, red, disco, temperatura y estado del sistema
Cuando tienes un servidor —ya sea un VPS, un servidor casero o una Raspberry Pi— hay una pregunta que siempre deberías poder responder:
¿Está mi servidor funcionando correctamente ahora mismo?
Muchos administradores principiantes instalan servicios y aplicaciones… pero no monitorizan el estado del sistema. El resultado suele ser:
- El disco se llena y el servidor se cae
- La CPU se dispara sin saber por qué
- El sistema se sobrecalienta
- Un proceso consume toda la memoria
- La red se satura
La buena noticia es que Linux incluye herramientas poderosas para saber exactamente qué está pasando dentro de tu servidor.
En esta guía aprenderás:
- Qué deberías monitorizar en un servidor Linux
- Las herramientas esenciales que todo sysadmin usa
- Cómo ver CPU, memoria y procesos
- Cómo comprobar red, temperatura y disco
- Qué instalar para tener monitoreo más avanzado
- Buenas prácticas de administración
Este artículo es evergreen, ideal como referencia para cualquier administrador de sistemas.
Qué deberías monitorizar en un servidor
Antes de ver herramientas, hay que entender qué métricas importan realmente.
Un servidor saludable debería tener controlados estos elementos:
CPU
- Uso total
- Procesos que consumen más recursos
- Load average
Memoria RAM
- Memoria usada
- Memoria libre
- Swap
Disco
- Espacio disponible
- Uso de particiones
- Salud del disco
Red
- Tráfico entrante y saliente
- Conexiones activas
- Puertos abiertos
Temperatura (hardware)
- CPU
- Sensores de la placa base
Procesos del sistema
- Qué servicios están activos
- Qué procesos consumen más recursos
Herramientas básicas que todo servidor Linux debería tener
Antes de empezar, instala algunas utilidades esenciales.
sudo apt update sudo apt install htop btop neofetch lm-sensors vnstat iotop ncdu
Estas herramientas te permitirán monitorizar casi todo el sistema.
Ver el estado general del sistema
uptime
Este comando muestra:
- cuánto tiempo lleva encendido el sistema
- usuarios conectados
- carga del sistema
uptime
Ejemplo:
16:40:12 up 12 days, 3:21, 1 user, load average: 0.12, 0.09, 0.05
Load average indica la carga del sistema en:
- 1 minuto
- 5 minutos
- 15 minutos
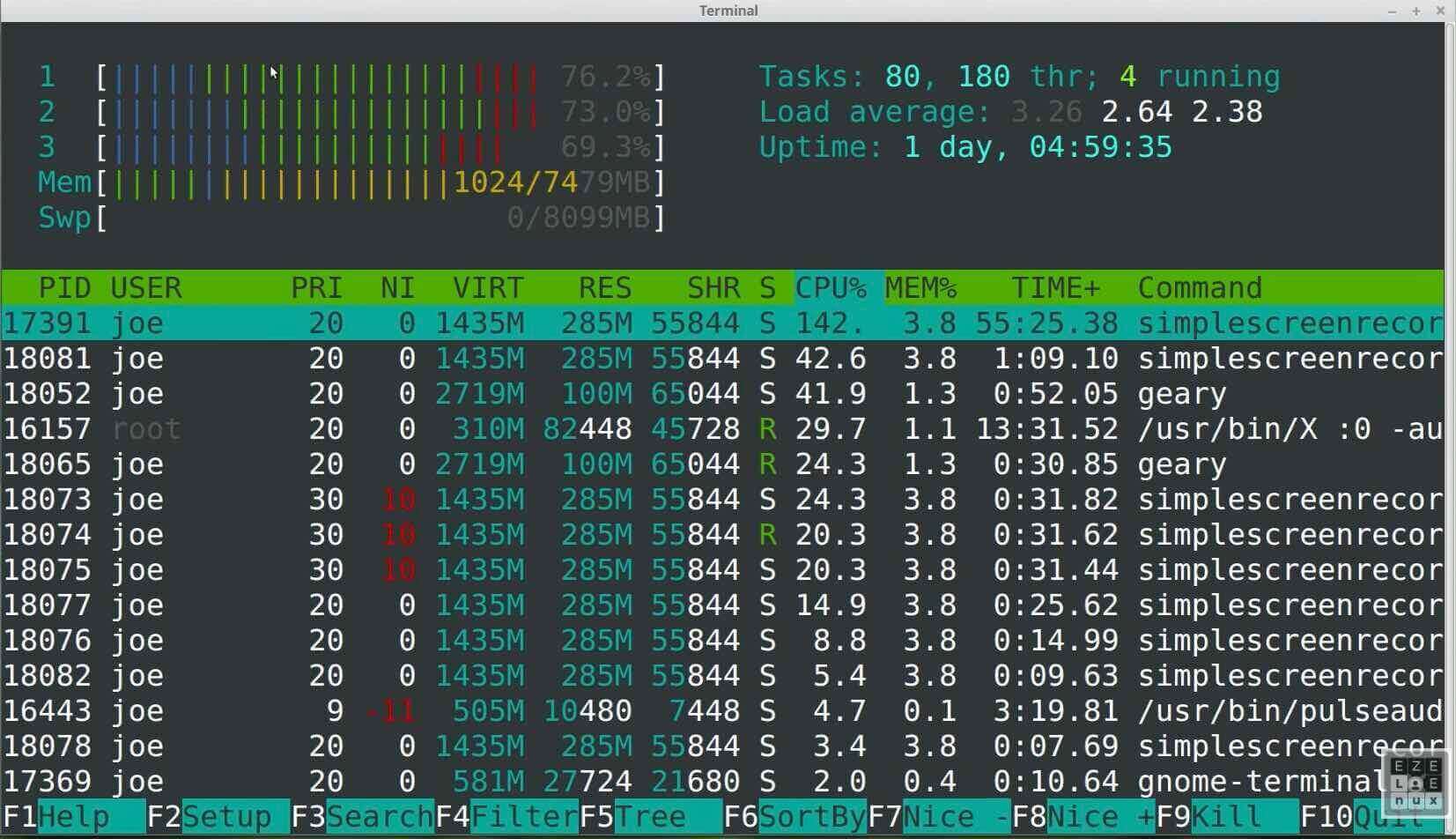
Monitorizar CPU y procesos
top
Es una herramienta clásica incluida en Linux.
top
Muestra:
- procesos activos
- uso de CPU
- uso de memoria
- PID de cada proceso
htop (recomendado)

Una versión más visual de top.
htop
Ventajas:
- interfaz clara
- permite matar procesos fácilmente
- muestra CPU por núcleo
- navegación sencilla
Controles útiles:
F9 → matar proceso F6 → ordenar procesos F5 → vista árbol
Monitorizar memoria RAM
free
free -h
Ejemplo:
total used free Mem: 7.7G 1.2G 4.8G Swap: 2.0G 0.0G 2.0G
La opción -h muestra valores legibles (GB, MB).
Monitorizar el uso del disco
df
Muestra espacio disponible en discos.
df -h
Ejemplo:
Filesystem Size Used Avail Use% /dev/sda1 50G 21G 26G 45%
ncdu (muy recomendado)
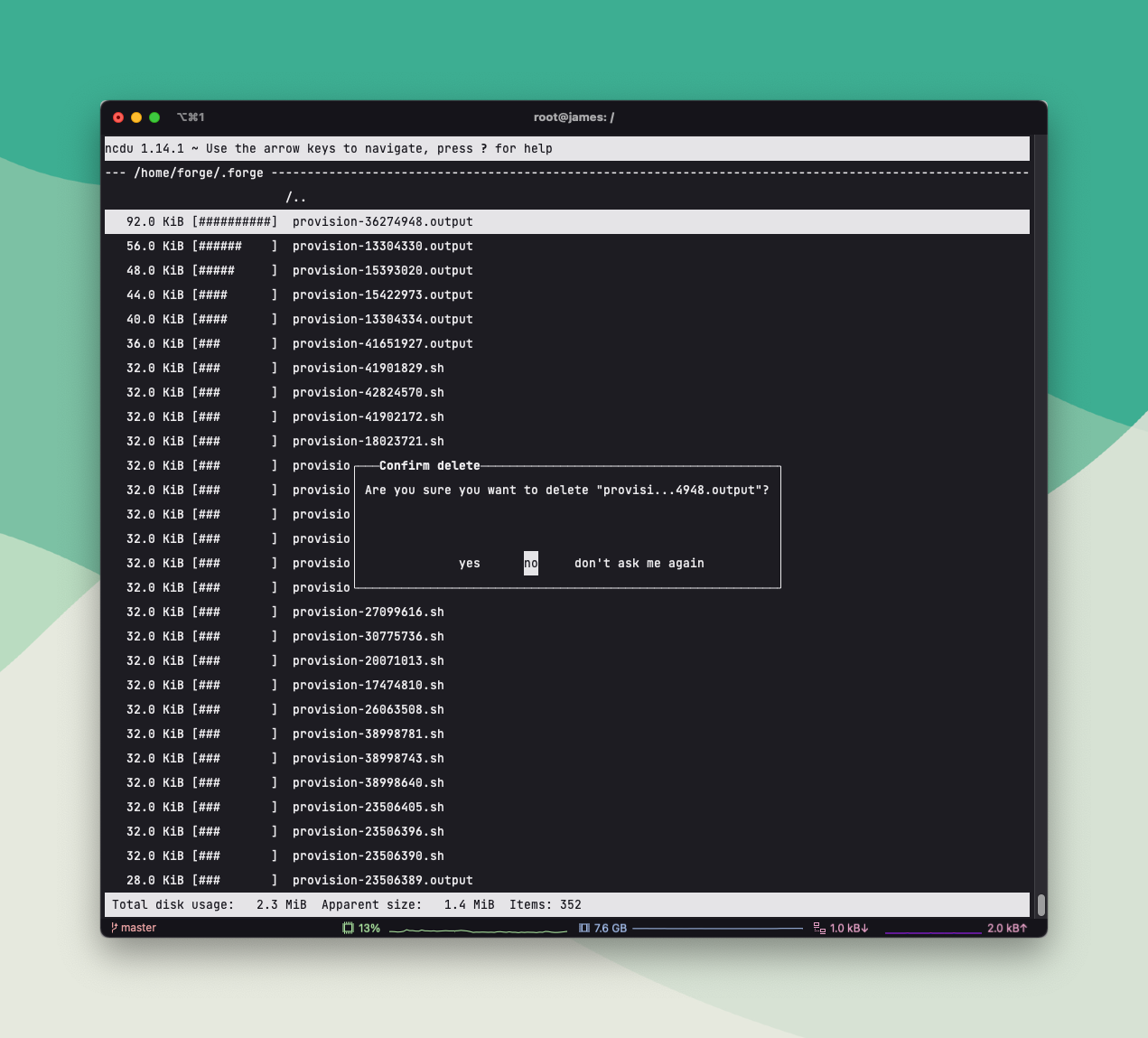
Una herramienta interactiva para ver qué carpetas ocupan espacio.
ncdu /
Es extremadamente útil cuando el servidor se llena.
Monitorizar red y tráfico
vnstat
Monitoriza tráfico de red.
vnstat
Ejemplo:
rx: 2.34 GB tx: 1.12 GB
También permite ver:
vnstat -d
Tráfico por día.
ss
Para ver conexiones activas.
ss -tulnp
Muestra:
- puertos abiertos
- servicios escuchando
- conexiones activas
Monitorizar uso del disco por procesos
iotop
sudo iotop
Muestra qué procesos están leyendo o escribiendo en disco.
Muy útil para detectar:
- backups
- procesos pesados
- malware
Monitorizar temperatura del hardware

Primero detecta sensores:
sudo sensors-detect
Luego ejecuta:
sensors
Ejemplo:
CPU Temp: 45°C
Ver información general del sistema
neofetch
neofetch
Muestra:
- distribución
- kernel
- RAM
- CPU
- uptime
Muy útil para diagnóstico rápido.
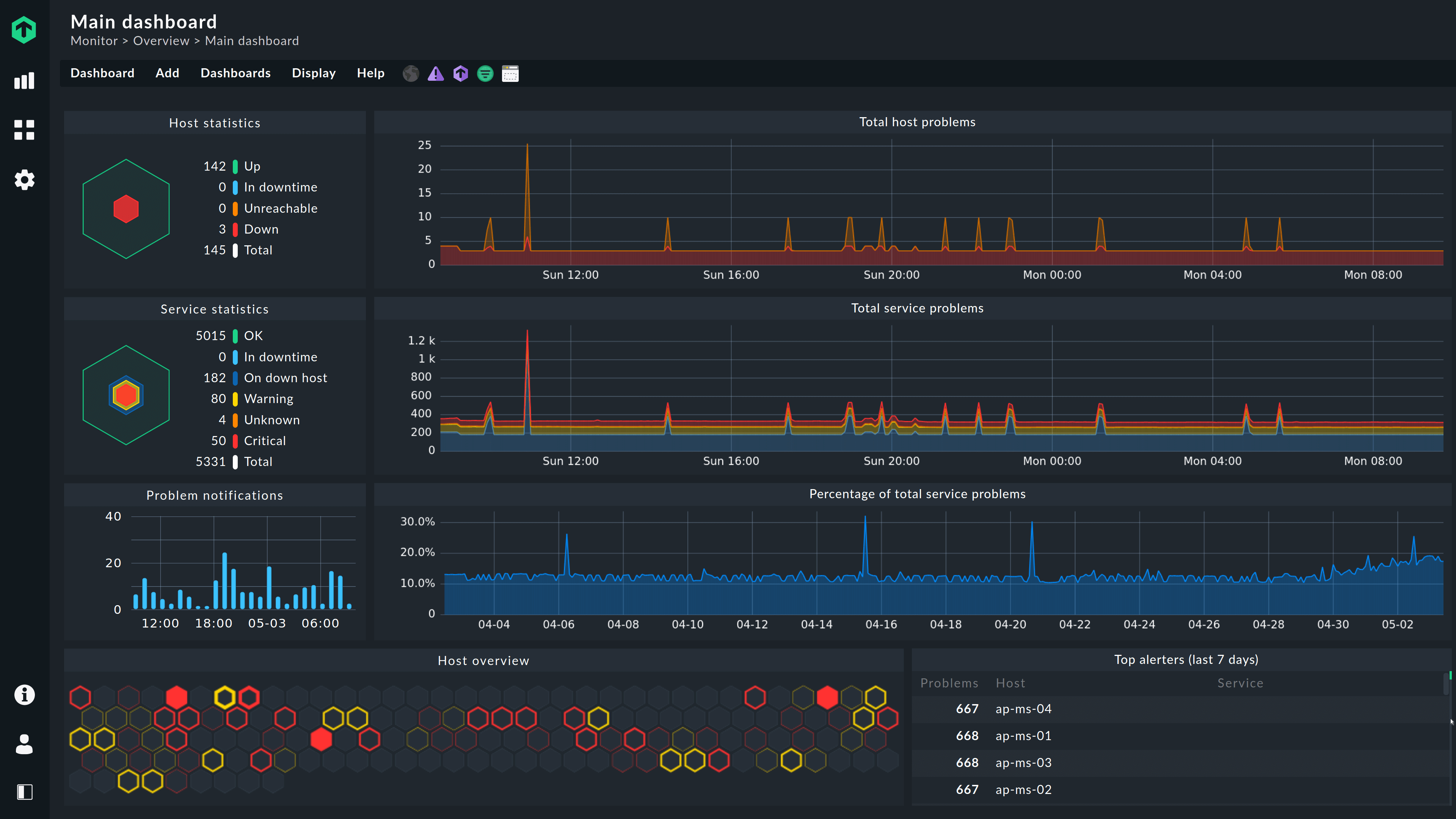
Monitorización moderna (recomendado para servidores)
Para algo más avanzado puedes usar:
Netdata
Dashboard web en tiempo real.
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
Permite ver:
- CPU
- RAM
- red
- discos
- procesos
Todo desde un navegador.
Prometheus + Grafana
Usado en infraestructura profesional.
Permite:
- dashboards
- métricas históricas
- alertas
Pero requiere configuración avanzada.
Buenas prácticas de monitoreo
Revisa tu servidor regularmente
Un administrador debería revisar:
- uso de disco
- logs
- procesos
Automatiza alertas
Puedes configurar alertas para:
- disco lleno
- CPU alta
- memoria baja
Mantén el sistema actualizado
sudo apt update && sudo apt upgrade
Revisa logs del sistema
journalctl -xe
Los logs revelan muchos problemas antes de que se vuelvan críticos.
Señales de que tu servidor tiene problemas
Presta atención si ves:
- Load average alto
- CPU constantemente al 100%
- Disco casi lleno
- Temperaturas altas
- Muchos procesos zombie
Conclusión:
Administrar un servidor no es solo instalar servicios.
También implica vigilar constantemente su estado.
Las herramientas que vimos hoy permiten:
- detectar problemas antes de que ocurran
- optimizar rendimiento
- mantener estabilidad
Con unos pocos comandos puedes entender exactamente qué está pasando dentro de tu servidor Linux.
Y eso es una de las habilidades más importantes para cualquier administrador de sistemas.
Post relacionados:
- Personaliza tu terminal en Linux como un profesional (guía completa y práctica)
- Qué es la terminal y para qué sirve (explicado fácil)
- Cómo funcionan los directorios en Linux (guía completa para entender el sistema)
Tags de este post
Preguntas frecuentes
--Revisión rápida diaria
--Revisión completa semanal
Ejemplo:
CPU de 4 núcleos:
Load 4 = CPU al límite
Load 8 = saturación
--Logs creciendo
--Backups acumulados
--Archivos temporales
Detectar problemas temprano evita caídas.
Consume pocos recursos y ofrece mucha información útil.